UTF-8
Från Rilpedia

UTF-8 (åtta-bitars Unicode transformationsformat) är en teckenkodning (längdvarierande) som används för att representera text kodad i Unicode, som en sekvens av bytes, till exempel i textfiler. Unicode använder upp till 21 bitar, vilket inte får plats i en byte.
UTF-8 är konstruerat så att tecken som tillhör ASCII-tabellen (som täcker A-Z, a-z, 0-9 samt vanligt förekommande interpunktion) kommer att kodas på samma sätt i både ASCII och UTF-8, och inga bytes som inte är ASCII-tecken kan misstolkas som ASCII-tecken. Det gör UTF-8 lämpligt för tillämpningar där man eventuellt tolkar vissa följder av ASCII-tecken speciellt (som nyckelord på något sätt), medan resten av texten bara kopieras vidare oförändrad - till exempel för webbsidor. HTML-koder (t.ex. <br>) blir oförändrade mot en traditionell 8-bitskodning, men man kan ändå få stöd för alla världens språk. Wikipedias sidor är kodade i UTF-8.
I program som inte uppdaterats för Unicode, eller av någon anledning tolkar byte-strömmen som något annat än UTF-8, kan visa fel tecken. Ett program som felaktigt tolkar byte-strömmen som om den vore kodad i Latin-1 (ISO/IEC 8859-1), kan om texten "knäckebröd av råg" är kodad i UTF-8, visa den som "knäckebröd av rÃ¥g". Detta är en välkänd typ av problem med de äldre 1-byteskodningarna som finns i hundratals versioner, men detta ska vara sista gången det inträffat. Nu när Unicode är infört och stöds överallt ska man som användare slippa alla textkodningsproblem för alltid.
Eftersom UTF-8 kodar på ett visst sätt (första byten för ett tecken har C0-F7 (hex), övriga bytes 80-BF), kan en modern texteditor eller webbläsare se i själva filen att den är gjord i UTF-8 och därmed Unicode, som det bara finns en version av, och alltid tolka filen som UTF-8 om den är det. Detta är en stor fördel mot nästan alla äldre kodningar, då det var svårt eller omöjligt att räkna ut kodningen om det inte direkt framgick. Nyare webbläsare gör denna beräkning, innan dess var sådana problem vanliga under en tid när Unicode var nyare, och webbläsarna inte stödde det bra. I Windows brukar Unicode-textfiler ha ett specialtecken först (U+FEFF, som inte visas), och med UTF-8 då blir de tre första bytena EF BB BF. Denna markering visar meddetsamma att att det rör sig om UTF-8. I Unix brukar man inte ha någon sådan markering, vilket inte är nödvändigt för att känna igen UTF-8.
UTF-8 är standardiserad av ISO/IEC 10646, Unicode, och även RFC 3629 (UTF-8, a transformation format of ISO/IEC 10646). Nedan ges en sammanfattning.
Innehåll |
Beskrivning
Tecken lagrade med UTF-8 varierar i längd, 1–4 bytes (oktetter). Om den mest signifikanta biten i den första byten (oktetten) är nolla, är det ett ASCII-tecken (kodat i en enda byte). Annars ger antalet mest signifikanta bitar som är etta (före första noll-biten) i första byten sekvensens längd, vilket kan vara två till fyra. Om sekvensen spänner över flera bytes, startar efterföljande oktetter (bytes) alltid med bitmönstret 10. Representationer som använder fler bytes än nödvändigt är felaktiga. Kodsekvenser som skulle representera surrogatkodpunkter (inom U+D800–U+DFFF, avsedda för UTF-16) är även de felaktiga. De kodpunkter (teckennummer) som kan representeras är begränsat till U+0000 - U+10FFFF (det är UTF-16 som sätter övre gränsen, UTF-8 möjliggör egentligen U+1FFFFF)
Eftersom UTF-32, UTF-16 och UTF-8 sträcker sig över samma kodpunkter, kan konvertering ske mellan dessa tre kodscheman utan förlust.
| Kodintervall hexadecimalt | UTF-16 | UTF-8 binärt | Anmärkning |
|---|---|---|---|
| U+0000 - U+007F: | 00000000 0xxxxxxx | 0xxxxxxx | UTF-8-kodningen är här samma som ASCII; bitsekvensen startar med värdet noll, liksom alla ASCII-koder |
| U+0080 - U+07FF: | 00000xxx xxxxxxxx | 110xxxxx 10xxxxxx | Bitsekvensen i första oktetten startar med lika många "1" som antalet oktetter (2-4), följt av "0". Följande oktetter startar med bitsekvensen "10" |
| U+0800 - U+FFFF (utom U+D800 - U+DFFF): |
xxxxxxxx xxxxxxxx | 1110xxxx 10xxxxxx 10xxxxxx | |
| U+10000 - U+10FFFF: | 110110xx xxxxxxxx 110111xx xxxxxxxx* | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | UTF-16 använder intervallet U+D800 - U+DFFF och 32 bits för att lagra sådana tecken. Ett offset av 0x10000 subtraheras för UTF-16, mest för att nå upp till U+10FFFF, annars skulle bara U+0FFFFF nås. |
Till exempel, tecknet alef (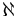 ), som har Unicode-kodpunkten U+05D0, kodas i UTF-8 på följande sätt:
), som har Unicode-kodpunkten U+05D0, kodas i UTF-8 på följande sätt:
- Tecknet finns inom intervallet 0x0080-0x07FF, vilket gör att det måste representeras av två bytes: 110x xxxx 10xx xxxx.
- Hexadecimala 0x05D0 är binärt 101 1101 0000.
- De elva bitarna stoppas i positionerna markerade med x ovan (man lägger till ledande 0-bitar när så behövs, men inte fler än nödvändigt): 1101 0111 1001 0000.
- Slutresultatet är två bytes, i hexadecimal form 0xD7 0x90.
De första 128 kodtecknen behöver bara en byte. Med två bytes kan UTF-8 representera 1920 olika kodtecken, med tre oktetter ryms 63488 teckenkoder (kodpunkter upp till 65536 / U+FFFF), 2048 surrogatkoder undantagna), och med fyra bytes kan alla övriga kodpunkter (utom surrogatkodpunkter) representeras.
Exempel på skriftsystem som kräver två bytes per tecken i UTF-8 är (de flesta) latinska tecken, grekiska, kyrilliska, armenska, hebreiska och arabiska. Därmot behöver japanska, kinesiska, koreanska, thailändska med flera språk tre bytes per tecken.
UTF-8 ger mindre filer än UTF-16 för alla språk som kräver max två bytes per tecken, eftersom det alltid finns blanktecken, komma med mera som kräver 1 byte. Text med latinskt alfabet ger mycket mindre filer än UTF-16 och obetydligt mer än 8-bitskodningar, eftersom de flesta bokstäver blir i intervallet A-Z. Däremot kräver många öst- och sydasiatiska språk mer utrymme för UTF-8 än andra kodningar. Särskilt i Indien har det varit kritik mot det då de hittills använt en egen 8-bitskodning som bara varit gjord för hindi och engelska. UTF-8 tar tre gånger så mycket minnesutrymme för hindi.
Historik
UTF-8 uppfanns av Ken Thompson och Rob Pike den 2 september 1992, under ett restaurangbesök i New Jersey.
Se även
- UTF-16, ett sätt att koda Unicode-texter i 16-bitars sekvenser (eller 2-bytes).
Externa länkar
- Unicode.se visar hur man ställer in sina webbplatser och andra databaser till UTF-8