Den perceptuella fuzzy-logic-modellen
Från Rilpedia

Den perceptuella fuzzy-logic-modellen (Fuzzy-logical model of perception, FLMP) är en
perceptionsmodell, utarbetad av Dominic Massaro verksam vid University of California, Santa Cruz. FLMP kan tillämpas inom många områden, däribland multimodal talperception. I vardagligt tal är talpercetion en audiovisuell process där lyssnaren, förutom ljud, även har tillgång till visuell information från talarens ansikte och dennes talgester. Det är uppenbart att den visuella signalen underlättar förståelsen i bullriga miljöer. Men den visuella signalen påverkar det vi hör, även då den akustiska signalen inte är störd av brus. Ett exempel på detta är McGurk-effekten: Ett ansikte som till synes uttalar [gaga], då den akustiska signalen är utbytt mot [baba] percipieras som [dada] av en överväldigande majoritet. Perceptet är i och med detta en sammansmältning av informationen från de båda modaliteterna.
Enligt FLMP sker perceptionen i tre steg: Evaluering, Integration och Avgörande.
Innehåll |
Evaluering
Det första steget innebär att informationen evalueras i de båda modaliteterna (den auditiva och den visuella) var för sig. Evalueringen innebär att den inkommande signalen matchas mot lagrade prototyper av möjliga responser. Signalens förhållande till var och en av prototyperna registreras som graderat sanningsvärde på en skala 0 till 1. Till skillnad från sannolikheter kan summan av de olika graderna av sanningsvärde för de olika prototyperna överstiga 1.
Integration
FLMP utgår från Baysiansk integration. Trots att Bayes sats opererar på sannolikheter, tillämpas den här istället på graderat sanningsvärde.
Bayes sats säger att:
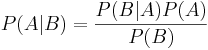
Dvs. sannolikheten för A betingat B är lika med sannolikheten för att B betingat A, multiplicerat med sannolikheten för A, delat med sannolikheten för B.
I termer av sannolikhet för percipierat språkljud ci, givet den akustiska evidensen A och den visuella evidensen V får vi:
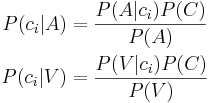
Sannolikheten för två händelser, A och B, är detsamma som produkten av dessa händelser för sig, givet att de är oberoende:
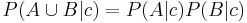
Detta ger följande responssannolikheter för språkljudet ci:
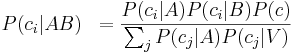
Eftersom språkljudskategorin ci existerar:
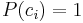
Avgörande
Det slutgiltiga perceptet bygger på de baysianska responssannolikheterna för var och en av de tänkbara percepten. Dessa räknades ut i det tidigare steget. En viktig detalj är att perceptet enligt FLMP är amodalt. På denna punkt skiljer sig modellen från gestuella och auditiva talperceptionsteorier.
Källor
- Massaro W.M. & Stork D.G., Speech Recognition and Sensory integration (1998) American Scientist. 86. sid. 236-244.
- McGurk H. & MacDonald J., Hearing lips and seeing voices (1976) Nature. 264. sid. 746-748.
- Sumby, W.H. & I. Pollack, Visual contribution to speech intelligibility in noise (1954) Journal of the Acoustical Society of America. 26. sid. 212-215.