Enkel logistisk regression
Från Rilpedia

Logistisk regression är en matematisk metod med vilken man kan analysera mätdata.
Metoden lämpar sig bäst då man är intresserad av att undersöka om det finns ett samband mellan en responsvariabel (Y), som endast kan anta två möjliga värden, och en förklarande variabel (X).
Exempel:
Man är intresserad av att studera om det finns ett samband mellan mängden tjära i lungorna (X) och huruvida lungcancer föreligger (Y). Responsvariabeln kan endast anta de två värdena 'Ja' eller 'Nej', medan den förklarande variabeln (i princip) kan anta vilka positiva värden som helst.
Det är inte meningsfullt att försöka beskriva ett eventuellt samband mellan X och Y på en linjär form, så som är brukligt vid enkel linjär regression:
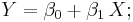
Anledningen till detta är att uttrycket β0 + β1X representerar ett reellt tal, medan vänsterledet, Y, endast kan anta två möjliga värden. (Det finns fler reella tal än vad som är möjliga att räkna upp; Man säger att det finns överuppräkneligt många reella tal.)
Vi är intresserade av ett samband mellan sannolikheten att Y skall anta värdet 'Ja', och den förklarande variabeln X:
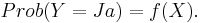
Eftersom en sannolikhet är ett tal som ligger mellan värdena noll och ett, måste funktionen f vara sådan att då X är ett reellt tal är f(X) ett tal mellan noll och ett:
![f : \mathbb{R} \Longrightarrow [0,1].](/w/images/sv.rilpedia.org/math/4/8/d/48d08b1d792e353e7f8a7dd15ae6c6a2.png)
I den enkla logistiska regressionsmodellen definieras funktionen f indirekt av följande samband:
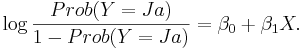
- Notera att om p är ett tal mellan noll och ett, så är
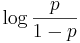 ett reellt tal:
ett reellt tal:
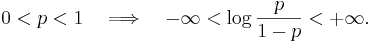
Då man jämför denna matematiska modell över sambandet mellan X och Y med gjorda mätningar på X och noteringa av förekomsten av lungcancer, får man inte en perfekt överensstämmelse. De avvikelser som noteras kan ha två orsaker:
- (1) Den matematiska modellen är olämplig och det förekommer slumpeffekter, eller
- (2) Den matematiska modellen är lämplig och det förekommer slumpeffekter.
Som synes kan man inte bli kvitt slumpeffekterna. Vad man däremot kan göra är att försöka att beskriva dem genom att undersöka deras frekvensfunktion.
Den enkla logistiska regressionsmodellen utgår från att avvikelserna (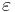 ) mellan uttrycket β0 + β1X och
) mellan uttrycket β0 + β1X och 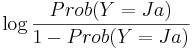 är bestämda av den så kallade normalfördelningen, vars fördelningsfunktion är:
är bestämda av den så kallade normalfördelningen, vars fördelningsfunktion är:
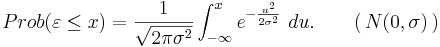
Man säger att avvikelsen, , mellan modell-Y och mätdata-Y är N(0,σ)-fördelad.
Den enkla logistiska regressionsmodellen tar hänsyn både till sambandet mellan X och Y och till slumpens påverkan:
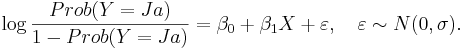
Sambandet mellan Prob(Y = Ja) och X får vi genom att invertera ovanstående ekvation:
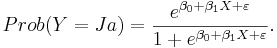
Det är viktigt att notera att slupeffekterna () kommer in multiplikativt i denna modell (som exponenter), till skillnad från additivt, som vid enkel- och multipel linjär regression. Detta gör det svårt att bestämma den frekvensfunktion som styr det slumpmässiga beteendet hos kvoten 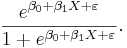
Referenser
- D. Collett, Modelling binary data, Second edition, (2003), Chapman & Hall/CRC
- G. Casella och R.L. Berger, Statistical inference, Second edition, (2002), Duxbury advanced series